Migrating data between different configurations is not a trivial task. As always, there are several solutions, but not all of them are optimal. Let's try to understand the nuances of data transfer and choose a universal strategy for solving such issues.
The problem of data migration (this is purely about 1C company products) from one solution to another did not arise yesterday. The 1C company is well aware of the difficulties developers face when creating migrations, so it tries its best to help with tools.
During the development of the platform, the company introduced a number of universal tools, as well as technologies that simplify data transfer. They are built into everything. standard solutions and the problem of migrations between identical configurations was generally solved. The victory is once again confirmed by the close integration of standard solutions.
With migrations between non-standard solutions, the situation is somewhat more complicated. A wide range of technologies allows developers to independently choose the best way to solve a problem from their point of view.
Let's consider some of them:
- exchange via text files;
- use of exchange plans;
- etc.
Each of them has its pros and cons. To summarize, the main disadvantage will be verbosity. Independent implementation of migration algorithms is fraught with significant time costs, as well as a long debugging process. I don’t even want to talk about the further support of such decisions.
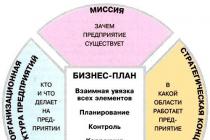
The complexity and high cost of maintenance prompted the 1C company to create a universal solution. Technology that allows you to simplify the development and support of migrations as much as possible. As a result, the idea was implemented in the form of a separate configuration - "Data Conversion".

Data conversion - standard solution, self-configuration. Any user with an ITS:Prof subscription can download this package completely free of charge from the user support site or the ITS disk. Installation is performed in a standard way - like all other standard solutions from 1C.
Now a little about the pros of the solution. Let's start with the most important - versatility. The solution is not tailored to certain platform configurations/versions. It works equally well with both standard configurations and self-written ones. Developers get a universal technology and a standardized approach to creating new migrations. The versatility of the solution allows you to prepare migrations even for platforms other than 1C:Enterprise.
The second bold plus is visual aids. Simple migrations are created without programming. Yes, yes, without a single line of code! For this alone, it is worth spending time learning the technology once, and then using invaluable skills repeatedly.
The third advantage I would note is the absence of restrictions on data distribution. The developer himself chooses the method of delivering data to the receiver configuration. Two options are available out of the box: uploading to an xml file and direct connection to the infobase (COM/OLE).
Learning architecture
We already know that data conversion can work wonders, but it is not yet clear what the technical advantages are. The first thing to learn is that any data migration (conversion) is based on exchange rules. Exchange rules - a regular xml file with a description of the structure into which data will be uploaded from IB. The service processing that performs data upload/download analyzes the exchange rules and performs the upload based on them. During the download, the reverse process occurs.
The “KD” configuration is a kind of visual constructor with which the developer creates exchange rules. It does not know how to upload data. Additional external service processing included in the CD distribution kit is responsible for this. There are several of them (XX in the file name is the platform version number):
- MDXXExp.epf- processing allows you to upload a description of the infobase structure to an xml file. The description of the structure is loaded into the CD for further analysis and creation of exchange rules.
- V8ExchanXX.epf- uploads/downloads data from the infobase in accordance with the exchange rules. In most typical configurations, processing is available out of the box (see the “Service” menu item). Processing is universal and is not tied to any specific configurations/rules.
Okay, now based on all of the above, let's define the stages of developing a new conversion:
- Task definition. It is necessary to clearly understand what data needs to be transferred (from which configuration objects) and, most importantly, where to transfer.
- Preparation of a description of configuration structures (Source/Receiver) for subsequent loading into the CD. The task is solved by service processing MDXXExp.epf.
- Loading prepared descriptions of structures in IS.
- Creating exchange rules using visual means of CD.
- Uploading/downloading according to the created data conversion rules by using V8ExchanXX.epf processing.
- Debugging exchange rules (if necessary).

The simplest conversion
For the demonstration, we need two deployed configurations. I decided to stop at the option: “Trade Management” 10th edition and a small self-written solution. The task will be to transfer data from the typical UT configuration. For brevity, we will call the self-written solution “Receiver”, and trade management “Source”. Let's start solving the problem by transferring the elements of the "Nomenclature" directory.
First of all, let's take a look at the data conversion scheme and reread the list of actions that need to be done. Then we launch the “Source” configuration and open the service processing MD82Exp.epf in it.
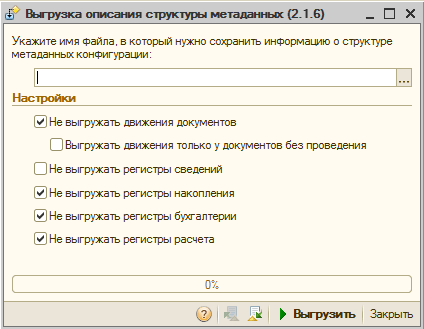
The processing interface does not shine with an abundance of settings. The user only needs to specify the types of metadata objects that will not fall into the description of the structure. In most cases, these settings do not need to be changed, because there is no particular point in unloading movements in accumulation registers (as an example).
It is more correct to form the movement during the holding of documents in the receiver. All movements will be made by the document itself after the transfer. The second argument in defense of the default settings is to reduce the size of the uploaded file.
Some documents (especially in typical configurations) form movements in multiple registers. Unloading all this economy will make the resulting XML file too large. This can make subsequent transportation and loading into the receiver base difficult. The larger the data file, the more RAM is required to process it. During my practice, I happened to encounter indecently large upload files. Such files completely refused to be parsed by standard means.
So, we leave all the default settings and upload the configuration description to a file. We repeat the same procedure for the second base.

Open the CD and select from the main menu “Directories” -> “Configurations”. The directory stores descriptions of the structures of all configurations that can be used to create conversions. We load the configuration description once, and then we can use it repeatedly to create different conversions.

In the directory window, press the button “ Add” and in the window that appears, select a file with a description of the configuration. Check the box “Upload to new configuration” and click on the button “Perform upload”. We perform similar actions with the description of the structure of the second configuration.

Now everything is ready to create the exchange rules. In the main CD menu, select “References” -> “Conversions”. Adding a new element. In the window for creating a new conversion, you need to specify: the source configuration (select UT) and the receiver configuration (select "Receiver"). Next, open the “Advanced” tab and fill in the following fields:
- exchange rules file name - created exchange rules will be saved under this name. The file name can be changed at any time, but it's best to set it now. This will save time in the future. I named the rules for the demo: "rules-ut-to-priemnik.xml".
- name - the name of the conversion. The name can be absolutely anything, I limited myself to “Demo. UT to the Receiver”.

That's it, click "Ok". Immediately, a window appears in front of us asking us to create all the rules automatically. Agreeing to such a tempting offer will give the wizard a command to automatically analyze the description of the selected configurations and independently generate exchange rules.

Let's dot the "and" right away. The master will not be able to generate anything serious. However, this possibility should not be discounted. If you need to establish an exchange between identical configurations, then the services of a wizard will be very helpful. For our example, manual mode is preferable.

Let's take a closer look at the "Exchange rules settings" window. The interface may seem slightly confusing - a large number of tabs stuffed with controls. In fact, everything is not so difficult, you start to get used to this madness after a few hours of working with the application.
On this stage we are interested in two tabs: “Object conversion rules” and “Data upload rules”. On the first one, we have to set up matching rules, i.e. compare objects of two configurations. On the second one, determine the possible objects that will be available to the user for unloading.
In the second half of the “Object conversion rules” tab there is an additional panel with two tabs: “Property conversion” and “ Value conversion". The first one will select the properties (requisites) of the selected object, and the second one is necessary for working with predefined values (for example, predefined dictionary elements or enumeration elements).
Great, now let's create conversion rules for directories. You can perform this action in two ways: use the object synchronization wizard (click “”) or add matches for each object manually.
To save space, we will use the first option. In the wizard window, uncheck the box “ Documentation” (we are only interested in directories) and expand the group “ Reference books". We carefully scroll through the list and look at the names of directories that can be compared.

In my case, there are three such directories: Nomenclature, Organizations and Warehouses. There is also a Clients directory that performs the same semantic load as “ Counterparties” from configuration “ UT". True, the master could not compare them due to their excellent names.
We can fix this defect ourselves. Find in the window Object Mappings» handbook « Clients”, and in the column “Source” select the reference book “Counterparties”. Then check the box in the "Type" column and click the "Ok" button.
The Object Synchronization Wizard will prompt you to automatically create rules for converting the properties of all selected objects. Properties will be matched by name, and for our demonstration this will be quite enough, we agree. The next question will be a proposal to create upload rules. Let's agree to it.

The basis for the exchange rules is ready. We chose the objects for synchronization, and the rules for converting properties and uploading rules were created automatically. Let's save the exchange rules to a file, then open the IB “Source” (in my case, it is UT) and start service processing in it V8Exchan82.epf.

First of all, in the processing window, select the exchange rules we created. We answer the question of loading the rules in the affirmative. Processing will analyze the exchange rules and build a tree of the same name for objects available for unloading. For this tree, we can set all sorts of filters or exchange nodes, by changing which we need to select data. We want to upload absolutely all the data, so there is no need to install filters.
After the process of uploading data to a file is completed, go to IB " Receiver". We also open processing in it V8Exchan82.epf, only this time we go to the “Loading data” tab. Select the data file and click the "Upload" button. Everything, the data was successfully transferred.
Tasks from the real world
The first demo could be misleading. Everything looks quite simple and logical. Actually this is not true. IN real work problems arise that are difficult or completely impossible to solve with visual means alone (without programming).
In order not to be disappointed in technology, I have prepared some real tasks. You will definitely come across them at work. They do not look so trivial and make you look at data conversion from a new angle. Carefully consider the presented examples, and feel free to use them as snippets when solving real problems.
Task number 1. Fill in the missing details
Suppose we need to transfer the directory “ Counterparties". The receiver has a similar reference book “Clients” for this. It is completely suitable for data storage, but it has props “ Organization”, allowing you to separate counterparties by belonging to the organization. By default, all counterparties must belong to the current organization (it can be obtained from the constant of the same name).
There are several solutions to the problem. We will consider the option of filling in the props “ Organization” right in the base “ Receiver”, i.e. at the time of data loading. The current organization is stored in a constant, so there is no barrier to getting this value. Let's open the object conversion rule (hereinafter referred to as FRP) “ Clients” (double click on the object) and in the rules setup wizard, go to the “Event handlers” section. In the list of handlers we find “ After loading”.
Let's describe the code for getting the current organization with subsequent assignment to the attribute. At the moment the “After loading” handler is triggered, the object will be fully formed, but not yet written to the database. No one forbids us to change it at our discretion:
If NOT Object.ThisGroup Then Object.Organization = Constants.CurrentOrganization.Get(); EndIf;
Before filling in the props " Organization» it is necessary to check the value of the attribute « This group". For the guide " Clients» the hierarchical flag is set, so checking for a group is necessary. Similarly, filling in any details is performed. Be sure to read the help for other handler options " AfterLoading". For example, among them there is a parameter " Refusal". If it is assigned the value "True", then the object will not be written to the database. Thus, it becomes possible to limit objects for writing at the time of loading.
Task number 2. Details in the information register
In the handbook " Counterparties"UT configuration, there are details" Buyer" And " Provider". Both props are of type “ boolean” and are used to determine the type of counterparty. In IB " Receiver”, at the reference book “ Clients“There are no similar details, but there is a register of information” Types of Clients". It performs a similar function and can store multiple tags for a single client. Our task is to transfer the values of the details to separate records of the information register.
Unfortunately, visual means alone cannot cope here either. Let's start small, create a new PCO for the information register " Types of Clients". Don't list anything as a source. Refuse automatic creation of upload rules.
The next step is to create the upload rules. Go to the appropriate tab and click the " Add". In the window for adding upload rules, fill in:
- sampling method. Change to “Arbitrary algorithm”;
- conversion rule. Select the information register “Customer Types”;
- Code (name) of the rule. We write it as “Uploading Client Species”;

Now you need to write the code for selecting data for uploading. This is where the parameter “ Data sampling". In it, we can place a collection with a prepared data set. Parameter " Data sampling” can take different values - query result, selection, collections of values, etc. We initialize it as a table of values with two columns: client and client type.
Below is the event handler code “ Before processing". It initializes the parameter “ Data sampling” followed by filling in data from the directory “ Counterparties". Here it is worth paying attention to filling in the column “ Client Type". In “UT”, we have features of the “Boolean” type, and in the recipient, an enumeration.
At this stage, we cannot bring them to the desired type (it is not in the UT), so for now we will leave it in the form of strings. You don’t have to do this, but I immediately want to show how to cast to a missing type in the source.
DataFetch = NewValueTable(); Data Selection.Columns.Add("Client"); Data Selection.Columns.Add("ClientType"); Selecting DataFrom the Directory = Directories.Contractors.Select(); While Fetching DataFromCatalog.Next() Loop If FetchingDataFromCatalog.ThisGroup Then Continue; EndIf; If DataFetchFromCatalog.Buyer Then NewString = DataFetch.Add(); NewString.Client = SamplingDataFromCatalog.Reference; NewString.ClientType = "Buyer"; EndIf; If DataFetchFromCatalog.Provider Then NewString = DataFetch.Add(); NewString.Client = SamplingDataFromCatalog.Reference; NewString.ClientType = "Supplier"; EndIf; EndCycle;
Save the data upload rule and return to the “ Object Conversion Rules". Let's add for the information register “ Types of Clients” property conversion rules: client and client type. We leave the source empty, and in the “Before unloading” event handler we write:
//For the "Client" property Value = Source.Client; //For the “CustomerType” property If Source.Customer = "Buyer" Then Expression = "Enumerations.CustomerTypes.Buyer" ElseIf Source.Customer = "Supplier" Then Expression = "Enumerations.CustomerTypes.Supplier"; EndIf;
In the listing, the details are filled in based on the data selection made. We pass the client simply as a link, and write the type of client in the parameter " Expression". The data of this parameter will be interpreted in the receiver, and when executed, the attribute will be filled in with the correct value from the enumeration.
That's it, the exchange rules are ready. The considered example turned out to be quite universal. A similar approach is often used when transferring data from configurations created on the 7.7 platform. A striking example of this is the transfer of periodic details.

Task number 3. Tabular Tricks
Often there are tasks that require posting rows of one tabular part into several. For example, in the initial configuration, services and goods are registered in one tabular section, while the storage of these entities is separated in the receiver. Again, the problem cannot be solved by visual means. Here it is convenient to take the solution of the second problem as a basis.
We make a data upload rule, specify an arbitrary algorithm, and write a query in the “Before upload” handler to get data from the tabular section.
To save space, I will not give the code (you can always refer to the source code) of the request - there is nothing unusual in it. We sort through the resulting sample, and place the sorted results in the already familiar parameter “ Data sampling". Again, it is convenient to use a table of values as a collection:
DataFetch = NewValueTable(); //Here there will be one more tabular section Data Selection.Columns.Add("Products"); //Here there will also be a tabular section Data Selection.Columns.Add("Services"); Selecting Data from.Columns.Add(“Link”);
Task number 4. Transferring data to an operation
If an organization uses several accounting systems, then sooner or later there will be a need for data migration with the subsequent formation of postings.
In the configuration " BP"there is a universal document" Operation” and it is ideal for forming more wires. Here's just one problem - the document is made cunningly, and it's not so easy to transfer data into it.
An example of such a conversion can be found in the source code for the article. The amount of code turned out to be quite large, so there is no point in publishing it for the article. Let me just say that the upload again uses an arbitrary algorithm in the rules for uploading data.
Task number 5. Synchronizing data across multiple attributes
We've already covered a few examples, but so far we haven't talked about object synchronization during migration. Let's imagine that we need to transfer counterparties and some of them are probably in the receiver database. How to transfer data and prevent duplicates? In this regard, CD offers several ways to synchronize transferred objects.
The first one is by unique identifier. Many objects have a unique identifier that guarantees uniqueness within a table. For example, in the handbook " Counterparties” cannot have two elements with the same ID. The CD makes a calculation for this, and for all created PSPs, search by identifier is immediately enabled by default. During the creation of the PSP, you should have noticed the magnifying glass icon next to the object name.
Synchronize by a unique identifier is a reliable method, but it is far from always appropriate. When merging directories “ Counterparties” (from several different systems) he is of little help.
In such cases, it is more correct to synchronize objects according to several criteria. It is more correct to search for counterparties by TIN, KPP, Name or split the search into several stages.
Data conversion does not limit the developer in defining the search criteria. Let's consider an abstract example. Suppose we need to synchronize directories “ Counterparties” from different information bases. Let's prepare a PCP and in the settings of the rules for converting an object, check the box “ Continue searching the search fields if the receiver object is not found by ID". With this action, we immediately defined two search criteria - by a unique identifier and arbitrary fields.
We have the right to choose the fields ourselves. Having noted the TIN, KPP, Name, we will immediately indicate several search criteria. Comfortable? Quite, but again, this is not enough. And what if we want to change the search criteria? For example, first we search for a bunch of TIN + KPP, and if we don’t find anything, then we start trying our luck with the name.
It is quite possible to implement such an algorithm. In the event handler Search fields” we can specify up to 10 search criteria and for each of them define its own composition of the search fields:
If SearchOptionNumber = 1 then SearchPropertyNameString = “TIN, KPP”; ElseIfSearchVariantNumber = 2 ThenSearchPropertyNameString = “Name”; EndIf;
There are always multiple solutions.
Any task has several solutions, and transferring data between different configurations is no exception. Each developer has the right to choose his own solution path, but if you constantly have to develop complex data migrations, then I strongly recommend paying attention to the "" configuration. Let at first you have to invest resources (time) in training, but they will more than pay off on the first more or less serious project.
In my opinion, the 1C company undeservedly bypasses the topic of using data conversion. For the entire time of the existence of the technology, only one book has been published on it: “1C: Enterprise 8. Data conversion: exchange between application solutions”. The book is quite old (2008), but it is still desirable to familiarize yourself with it.
Platform knowledge is still required
» is a universal tool, but if you plan to use it to create data migrations from configurations developed for the 1C:Enterprise 7.7 platform, then you will have to spend time getting to know the built-in language. The syntax and ideology of the language is very different, so you have to spend time learning. The rest of the principle remains the same.
1. Introduction.
2. What you need: 1C configuration: Data conversion 2. * and processing from the package. For an example of tasks, we take the configurations 1C: Trade Management 11 and 1C: BP 3.*.
So, to develop rules for uploading data to 1C, you will need the 1C configuration: Object Conversion 2, as well as the processing included in the package.
For example, we have already deployed the conversion base and launched it.
We will write the development of exchange rules between the configuration 1C: Trade Management 11 and 1C: Enterprise Accounting 3 (UT / BUH exchange rules).
3. We will need Processing to unload the metadata structure and exchange.
The first thing you need to get for development is files with a metadata structure. This is done using metadata structure unloading processing included in the object conversion package.

Actually, in the unpacked configuration directory for configurations on managed forms we are interested in processing MD83Exp.epf. If the unloading needs to be done from configurations on regular forms, then MD82Exp.epf processing is used. This is if, for example, you need to get a structure from such configurations as 1C: UT 10, 1C: Management manufacturing plant 1.3, 1C: Integrated automation 1.1, 1C: Zup 2.5 and so on.
Further, to upload and download data in 1C using our rules, you will need the processing of "Universal data exchange in XML format" V8Exchan83.epf for configurations on managed forms such as 1C: Trade Management 11. *, 1C BP 3, 1C: ERP 2. * and the like. And accordingly V8Exchan83.epf - for configurations on regular forms.
4. Uploading the configuration metadata structure 1C: Trade Management 11.3 and 1C: Enterprise Accounting 3.0. *
Let's start by unloading the metadata structure from the 1C configuration: Enterprise Accounting 3.
Open processing MD83Exp.epf

In the form of processing there are additional settings, where we can enable or disable the option to unload registers and movements in 1C. There is also a choice where the unloading will take place: on the 1C server or “on the client.” Specify the name of the file where the data structure will be unloaded. Similarly, we unload the configuration metadata structure Trade Management 11.
Now you need to load the configuration into the conversion database. This item can be reached both from the list of configurations and from the list of conversions. Let's just boot from the desktop:

In the dialog box, load the BP structure: 
And similarly - the structure of the Department of Trade. 
When the download is complete, a dialog box will appear where you can specify a name convenient for you. 

6. Creating rules for converting to 1C on specific example tasks.
Next, go to "Setting object rules", where we create a new setting.
In the dialog box for creating a conversion, select the "source" configuration and the "destination" configuration (which you have previously loaded) and click OK.

Since in this article I planned to show the creation “from scratch” and “without garbage”, I remind you that we do not automatically create anything. No prototypes.

We will not do anything in this dialog box, just click - "Close".
Let's create rules for unloading not one document into one, but one type into another, for example, the document Sales of Goods and Services from UT 11 with the necessary directories to the document Receipt of Goods and Services in BP 3.
So, we create a new PKO (the rule for converting objects into 1C)

Select the source Realization of Goods of Services and the receiver of Receipt of Goods of Services and click OK.
In this case, a dialog box will appear, where we again refuse the automatic creation of the PKC (Property Conversion Rules). Next, we select only the necessary ones.

But to the proposal to create a PVD (data upload rules), we answer “Yes”.


VDPs are created, which will be reflected in the processing of the universal XML exchange for selection:

Data conversion rules with empty property conversion rules will also be created.

Moreover, it is clear that by default it is proposed to search for the FSP by the internal identifier of the object. This is indicated by a magnifying glass near the PKO. We will do our own search, and we will do it by the document number and date at the beginning of the day.
Removing the search for UIO:

Now let's start matching the necessary properties (requisites) of the object. To do this, click "Property Synchronization" (label "1" on the screen). We remove the recursive creation of rules ("2"). We remove all the marked details ("3"). And we will choose for ourselves what we need.

For example, choose what you need:

I draw your attention to the fact that we will make the PKS of the counterparty into the organization, and the organization into the counterparty, and we will also compare some details that do not match in name, for example, “Currency” and “Document currency”.


Where we see that there are no conversion rules yet.
Let's start by details to go through and describe. First, we set up the search for the document as I wrote earlier, we unload and search for the document at the beginning of the date, and we will change the numbering. We will replace the first three characters with our prefix "UTB". And since in BP and UT the numbering is 11 characters each, we make a composite number: our prefix and 8 characters from the source. Screenshot example below.

We always unload documents that have not been carried out and without movement. We assume that the documents will be held in the receiver after checking by the user.
To do this, the PCS, having set how not held, 0 or 1, is used as a boolean.

Using the currency as an example, we create a rule for converting an object for the PCS. At the same time, we consider that there are currencies in both bases, and they must be synchronized by code. Therefore, we will not create all the PCSs in the CSP of currencies, but only add the Code for the search. Those. from the proposal to create a PCS for the object - we refuse.

The created Conversion Rule was substituted in the document's PQS for the SCS. And the default rule itself is offered by a unique identifier. We fix it, do a search in the code and set the property so as not to create a new object.
As a result, we get the option:

Further, by analogy, we create for the rest of the details of the PKO and PKS. Moreover, we set the search for an organization by counterparty and vice versa by TIN. This is what it looks like with minimal details (you can add if necessary).

For PKO Agreements of counterparties, we search for PKS Counterparty, name and owner.

Let's see how to specify the desired value in the enumeration type in the PCS. For example, the attribute "Operation Type". Here you can use various conditions and substitute values. For example, we need the “type of operation” to always be unloaded “Goods”, in this case it is enough to write the desired value in the “forehead” as a string.

The following shows how to set without difficulty and in most cases PKS for Settlement Multiplicity, Settlement Rate, Accounts.

For PKO Nomenclature, we leave the search by internal unique identifier. But I will pay attention to how you can redefine your group. For example, we agree that a new nomenclature will be unloaded from the configuration 1C: Trade Management 11, but it is necessary that the nomenclature be collected in a specific group “OurGroup”.

To implement this task, we create another PKO. Let's call it "Nomenclature Parent", which we will indicate in the parent's PDN in the conversion rule.
We set two searches: by name, where the name of our group is hardcoded, and the mandatory property of the attribute "ThisGroup" to true.

Since we have decided that all the nomenclature falls into our group, there is no need to unload the groups from UT 11 when unloading. To do this, in the Nomenclature PKO, in the “Before Unloading” event handler, we will put a filter that it is not necessary to unload the “Failure = Source” groups. This group;".

In the DRP (data upload rules) Implementation of Goods and Services, we will add a filter so that documents marked for deletion are not uploaded. To do this, in the PDP in the event handlers "BeforeUnloading" we will write the filter "Rejection = Object.DeletionMark;".

Save the developed rules to a file.

7. Summing up: Data upload and download using the developed data exchange rules.
We open in 1C: Trade Management 11 the processing "Universal data exchange in XML format" V8Exchan83.epf. 
The unloading has passed, now with the same processing we are loading into 1C: Enterprise Accounting 3.


Download completed. Let's check that it's loaded. So, the document is loaded, as we wanted - we have the Organization loaded into the counterparty, and the counterparty into the organization. Accounts are all downloaded and installed. We got the document number with our prefix and at the beginning of the day. All the details that have been registered have been filled in.

We check the loading of the nomenclature. We see that everything turned out as we planned.


We have created and filled in the details as we intended. There are many subtleties in the conversion and some simple but necessary things that help to accurately write the conversion. And this allows you to minimize errors, not spoil existing data and get rid of unnecessary garbage. This is one of the most simple examples. You can also do the conversion of one object into many, or vice versa, many - into one.
Now there is data conversion 3, it solves other problems. Therefore, conversion 2 is also needed. Good luck to everyone in learning and mastering.
Of course, if you are a programmer and this is your main job, you can try to write the conversion yourself. But if not, then you should value your time in your field of activity, and ask professionals to complete this task.
Specialized configuration "1C: Data conversion 2.0"
The release of the eighth version of the 1C:Enterprise platform has become a significant step in the development of automation systems. When designing the 1C:Enterprise 8 platform, the vast experience of using solutions based on the 1C:Enterprise 7.7 platform was taken into account: the built-in language of the platform and typical configurations were seriously redesigned, the structure of data storage and access was changed, new industry solutions were created that realize the advantages of the new platform . The use of previous language constructs in the new platform has become inappropriate.
To facilitate the solution of this problem (data transfer from version 7.7 to version 8), 1C has released a specialized configuration "Data Conversion 2.0". It was created to help specialists in solving various problems of data transfer. 1C has released ready-made rules for transferring data from configurations of the same type, for example, from 1C: Accounting 7.7 to 1C: Accounting 8, but users of non-standard or modified standard configurations when switching to the 1C: Enterprise 8 platform will have to create transfer rules data on your own.
With all the variety of private methods for solving data transfer problems, the range of issues to be solved remains practically unchanged:
Synchronization background information(creating new, updating existing elements of directories, deleting, saving or changing the hierarchy, branching data, transferring the history of changing the values of periodic details);
Synchronization of documents and operations (creation, modification of documents or transformation of one type of document into another, merging or reproduction);
Creation of sufficient initial conditions for accounting registers for maintaining economic activity(transfer of leftover goods, etc.).
Data storage structures in 1C:Enterprise of different versions and/or configurations are different, so data transfer is not just copying files or tables, but converting them. In order for the transformation to be unambiguous and correct, it is necessary to create and configure rules for data transfer. Creating and configuring rules for transferring data between different infobases is possible if the structure of data storage in the source and destination databases is known. The description of the configuration metadata structure should be unified. The Data Conversion 2.0 configuration is used to create and configure data transfer rules based on source and destination configuration metadata structure descriptions.
The process of transferring data between infobases consists of the following steps:
- 1. Creation of metadata description files.
- 2. Creation of Configurations in "Data Conversion".
- 3. Creation of the conversion itself.
- 4. Consistent creation of data conversion rules.
- 5. Consistent creation of data upload rules.
- 6. The actual procedure for unloading and loading data from one configuration to another.
Because the use of this specialized configuration is one of the most effective on this moment ways to solve problems of this kind, and in addition, a source of very useful for educational purposes personal experience, then to develop a mechanism for data exchange between the IS "Server: Rent Calculation" and "1C: Enterprise Accounting" for LLC "LLC", a method was chosen based on the use of the "Data Conversion 2.0" configuration.
Data conversion 2.0 and 2.1 is a 1C technological configuration implemented on platform versions from 8.1 to 8.3.
The main task of the tool is to write exchange rules between 1C 8 and 7 application solutions. The current version of data conversion today is 3.0.
Data conversion is a very useful configuration, with it you can solve not only the issue of transferring information from one infobase to another, but also, for example, converting information within one database.
The configuration is very convenient to use when .
Data conversion will be useful for any programmer: having the skills to create exchange rules is a serious plus for professional skills.
For learning how to work with the configuration, the best solution is practical tasks. Try to come up with tasks for yourself, for example: transfer any information from one database to another, turn a sales document into a receipt document, “drive” current accounting balances into a “balance entry” document and other tasks.
It will be very useful to understand the "typical" rules of the exchange 1C 8.3, there you can often find interesting examples of the implementation of tasks.
To comprehend the basics, you will need materials, consider them below.
Video instruction for converting
For the basics of setting up data exchange in 1C using the “1C Data Conversion” configuration, see the video for an example:
Materials, textbooks for studying 1C Data Conversion 2.0
There are not too many materials and documentation on the net, I tried to collect the most important and interesting materials:
0. First of all, I advise Ilya Leontiev's free video course, it is available at link.
1. I would advise first of all to use the built-in help in the configuration. It is really well written and well-implemented technically:

2. The second most important source of information is the site http://www.mykod.info/ (the site was closed), specialized just in data conversion. There you can download a large number of conversion materials.
3. Separately, I would like to highlight the training manual textbook - (author - Olga Kuznetsova).