I could not write down the changes for transfer to a distributed database, I contacted 1c support and offered the following. I decided to simply restart the application server and server with SQL. In general, you can check the box “Blocking scheduled
tasks included"
It also helped without rebooting.
Scheduled operations at the DBMS level for MS SQL Server
Instructions for performing routine operations at the DBMS level.
The information is applicable to the client-server version of 1C:Enterprise 8 when using the MS SQL Server DBMS.
General information
One of the most common causes of non-optimal system operation is incorrect or untimely execution of routine operations at the DBMS level. It is especially important to follow these routine procedures in large information systems ah, which work under significant load and serve a large number of users at the same time. The specificity of such systems is that the usual actions performed automatically by the DBMS (based on settings) are not enough for efficient operation.
If a running system exhibits any symptoms of performance problems, you should verify that the system is correctly configured and regularly performs all recommended routine maintenance at the DBMS level.
The execution of routine procedures should be automated. To automate these operations, it is recommended to use the built-in tools of MS SQL Server: Maintenance Plan. There are also other ways to automate these procedures. In this article, for each scheduled procedure, an example of its configuration is given using the Maintenance Plan for MS SQL Server 2005.
It is recommended to regularly monitor the timeliness and correctness of the implementation of these routine procedures.
Statistics update
MS SQL Server builds a query plan based on statistical information about the distribution of values in indexes and tables. Statistical information is collected on the basis of a part (sample) of data and is automatically updated when this data changes. Sometimes this is not enough for MS SQL Server to consistently build the most optimal plan for executing all queries.
In this case, query performance issues may occur. At the same time, characteristic signs of non-optimal work (non-optimal operations) are observed in query plans.
In order to guarantee the maximum correct work The MS SQL Server optimizer recommends that you regularly update the MS SQL database statistics.
To update statistics for all database tables, you must execute the following SQL query:
exec sp_msforeachtable N"UPDATE STATISTICS ? WITH FULLSCAN"
Updating statistics does not lead to locking tables, and will not interfere with the work of other users. Statistics can be updated as often as necessary. It should be taken into account that the load on the DBMS server during the statistics update will increase, which may adversely affect overall performance systems.
The optimal statistics update frequency depends on the magnitude and nature of the load on the system and is determined experimentally. It is recommended to update statistics at least once a day.
The above query updates the statistics for all tables in the database. In a real-life system, different tables require different statistics update rates. By analyzing query plans, you can determine which tables need the most frequent updates of statistics, and set up two (or more) different routine procedures: for frequently updated tables and for all other tables. This approach will significantly reduce the statistics update time and the impact of the statistics update process on the operation of the system as a whole.
Configuring automatic statistics update (MS SQL 2005)
Start MS SQL Server Management Studio and connect to the DBMS server. Open the Management folder and create new plan service:
Create a subplan (Add Subplan) and name it "Statistics Update". Add the Update Statistics Task to it from the taskbar:
Set up a statistics update schedule. It is recommended to update statistics at least once a day. If necessary, the statistics update frequency can be increased.
Set the task settings. To do this, double-click on the task in the lower right corner of the window. In the form that appears, specify the name of the database (or several databases) for which the statistics will be updated. In addition, you can specify for which tables to update statistics (if you do not know exactly which tables you need to specify, then set the value to All).
Updating statistics must be done with the Full Scan option enabled.
Save the created plan. When the time specified in the schedule arrives, statistics will be updated automatically.
Clearing the procedural cache
The MS SQL Server optimizer caches query plans for re-execution. This is done in order to save time spent compiling a query if the same query has already been executed and its plan is known.
It is possible that MS SQL Server, relying on outdated statistical information, will build a non-optimal query plan. This plan will be stored in the procedural cache and used when the same query is invoked again. If you have updated statistics but not cleared the procedural cache, then SQL Server may choose the old (non-optimal) query plan from the cache instead of building a new (better) plan.
To clear the procedural cache of MS SQL Server, you must execute the following SQL query:
This query should be run immediately after updating the statistics. Accordingly, the frequency of its execution should match the frequency of updating statistics.
Configuring Procedural Cache Clearing (MS SQL 2005)
Since the procedural cache needs to be cleared every time the statistics are updated, it is recommended to add this operation to the already created "Update statistics" subplan. To do this, open the subplan and add the Execute T-SQL Statement Task to its schema. Then you should connect the Update Statistics Task with an arrow to the new task.
In the text of the created Execute T-SQL Statement Task, you should specify the query "DBCC FREEPROCCACHE":
Index defragmentation
When you work intensively with database tables, the effect of fragmentation of indexes occurs, which can lead to a decrease in the efficiency of queries.
sp_msforeachtable N"DBCC INDEXDEFRAG (<имя базы данных>, ""?"")"
Index defragmentation does not block tables and will not interfere with the work of other users, however, it creates an additional load on SQL Server. The optimal frequency of performing this routine procedure should be selected in accordance with the load on the system and the effect obtained from defragmentation. We recommend that you defragment your indexes at least once a week.
It is possible to defragment one or more tables, not all tables in the database.
Configuring index defragmentation (MS SQL 2005)
In the previously created maintenance plan, create a new subplan named "Reindex". Add a Rebuild Index Task to it:
Set the execution schedule for the index defragmentation task. It is recommended to run the task at least once a week, and if the data in the database is highly volatile, even more often - up to once a day.
Reindexing database tables
Table reindexing includes a complete rebuilding of database table indexes, which leads to a significant optimization of their work. It is recommended to perform regular reindexing of database tables. To reindex all database tables, you must execute the following SQL query:
sp_msforeachtable N"DBCC DBREINDEX(""?"")"
Reindexing tables blocks them for the duration of their work, which can significantly affect the work of users. In this regard, reindexing is recommended to be performed during the minimum system load.
After reindexing, there is no need to defragment the indexes.
Setting up table reindexing (MS SQL 2005)
In the previously created maintenance plan, create a new subplan named "Index Defragmentation". Add a Rebuild Index Task to it:
Set the execution schedule for the table reindex task. It is recommended to run the task during the minimum load on the system, at least once a week.
Customize the task by specifying the database (or multiple databases) and selecting the required tables. If you do not know exactly which tables to specify, then set the value to All.
What are locks in 1C, why are they needed and how to avoid problems when working with them
Surely, many of you, when using information systems 1C Enterprise (1C 7.7, 1C 8.1, 1C 8.2, 1C 8.3), have encountered such a phenomenon as blocking. Moreover, as a rule, everyone calls this phenomenon differently: “1C locks”, “1C lock conflict”, “1C lock errors”, “1C transaction locks” and other names. Let's briefly understand what locks (not deadlocks) are, why they are needed and how to avoid problems when working with them. 
Locks themselves (including in 1C and in other systems) useful tool, which provides the ability to work sequentially with shared resources. For example, the concept of “shared resources” surrounds us in life, for example, while you are driving a car, no one else can drive it. Therefore, a car is a shared resource. And the second driver is waiting for you to arrive, for example, your wife / husband. You are both competing for a common resource - a car. Who will drive the car this moment You define at the conceptual level, but how should we be in automated systems??? To do this, they came up with a tool blocking, which organize the process of accessing a shared resource and define a queue. As a rule, in life, as in information systems (1C 7.7, 1C 8.1, 1C 8.2, 1C 8.3), there are a lot of common resources, and therefore there are also a lot of locks. Now the second important point - how long will your wife / husband wait for the release of your car, it is logical to assume that it will not last forever. Therefore, for locks, a timeout limit is set - otherwise, the timeout time. Timeout is the maximum amount of time that a rival participant (your wife/husband) can wait for a shared resource to be released. Then either he continues to wait for the same time, or he goes on foot. In 1C information systems, the expiration of the timeout ends with the message "1C lock conflict", "1C lock errors", "1C transaction locks", "Timeout on lock".
An important detail that should also be remembered is that locks (in particular in 1C) are explicit (set by the user) and implicit (set by the SQL platform). In the article we are talking about explicit locks, so they are always used in a transaction, hence it turns out that "1C Lock" and "1C Transaction Lock" are synonyms.
We decided that when the timeout is exceeded, an error message is displayed to the user, the waiting process itself looks like a sticky screen of the 1C information system for him. The following indicators influence the probability of a timeout message (1C errors for the user):
- Many 1C locks in a transaction;
- Transaction duration.
To minimize the messages associated with lock errors, it is necessary to either reduce the set of locks (optimize selectivity) or reduce the duration of transactions.
Now let's decide how these indicators can be influenced in a real 1C information system.
To reduce a lot of blocking:
In 1C:Enterprise 7.7:
Information system 1C 7.7. for locks, table locks are used, which paralyze the work of users. As a rule, more than 50 people in one database cannot work without errors, while problems can also appear in databases from 20 users.
Solution:
- Flexible locks 1C from the company "Softpoint". With their help, you not only optimize a lot of locks (replacing table locks with custom ones), but also speed up selections, searches, and reports.
Information system 1C 8.1., 1C 8.2., 1C 8.3. automatically uses redundant type locks (REPEATABLEREAD, SERIALIZABLE). This leads to a deterioration in the user experience from 100.
Solution:
- Managed locks 1C is a built-in tool of the 1C platform for more selective lock settings. To use it, the programmer must write special operators in the right places in the code to block the necessary ones ( in his opinion!) entries in the tables of the information system;
- Flexible locks 1C - Softpoint technology for replacing standard locks with custom ones.
To reduce the duration of transactions:
For any information systems 1C (1C 7.7., 1C 8.1, 1C 8.2, 1C 8.3), as well as for other information systems, similar approaches are used:
Check and correct setting routine maintenance databases (maintenance of files, indexes, statistics, temporary table databases, Windows and SQLServer setup);
Analysis and optimization of heavy 1C and SQL queries (index tuning, query rewriting);
Transaction redundancy check. In many cases, it is unreasonable to include operations in a transaction without realizing how this will affect the duration, and with it the performance.
- If you want to independently deal with the technical performance problems of 1C (1C 7.7, 1C 8.1, 1C 8.2, 1C 8.3) and other information systems , then for you a unique list of technical articles in our Almanac (Locks and deadlocks, heavy CPU and disk load, database maintenance and index tuning are just a small part of the technical materials that you will find there).
- If you would like to discuss performance issues with our expert or order a PerfExpert performance monitoring solutionthen leave a request and we will contact you as soon as possible.
Hi all!
The other day at work, I encountered a problem with locks, namely, the message "Lock conflict while executing a transaction. The maximum timeout for granting a lock has been exceeded" began to appear.
Obviously, there is no deadlock problem here, it's just that some session put a lock and "forgot" to remove it. At the same time, the problem threatened with serious consequences - the document Sales of goods and services was not carried out. About 100 people work in the database at a time, and it is impossible to perform a typical and frequent operation!
There were two solutions - rebooting the server or searching for a failed session. The first solution is simple and quick, but, as someone already wrote here, you can reboot the server until you get fired. Decided to go the second way.
The first day - the problem appeared in the afternoon, at first it seemed that the problem was in the remote user who was stuck in the Configurator. It looked like the execution just stopped at a point, and the lock, of course, was not released. After a couple of hours, we managed to release the configurator, but the problem did not go away. It was extremely undesirable to kill the configurator forcibly, perhaps they worked in it. After that, Google took over. I found an article on this site, which says how to find locks in the MS SQL DBMS, checked, there were no locks at the DBMS level. Strange. Further there were attempts to adjust those. magazine. Set up, what's next? In 15 minutes a couple of gigs of logs! How to read them, what to look for? Unknown.
I found an article on how to see what is blocked through SQL Trace. Even if I find it, then what? I need a session!
Closer to 16:00, when I realized that I couldn’t pull it any further, I made a reboot. In the hope that this will not happen again (and this was the first case in six months of work), I breathed a sigh of relief, everything worked. But in vain ... The second day - the same situation. I dug for an hour and a half, again incomprehensible attempts to google and so on. No results. Reboot. At the end of the day it happened again. Well, I think it’s great, I’ll calmly come home and sit, dig deeper. I come home, everything is fine. Sadly.
On the third day, I watched a webinar, talked about an interesting and effective method search for a problem. Remembered, but the problem did not arise any more. A week has passed and here it is - again blocking! I rub my hands and start to act.
The first is setting up the log. Yes, I can't do without it, but now I can read it. We set two events: the first is TLOCK, the second is TTIMEOUT. The first displays all blocking events, the second shows blockages that could not be established in the allotted time. In fact, most likely, only TTIMEOUT is enough.
We copy the technical log file to the allotted place, fly to the program, call the lock, receive a message and remove or rename the technical log file. We don't need tons of information about other blockings!
Go to the rphost_PID folder, find text files and search for the word TTIMEOUT. We see the line:
53:16.789126-0,TTIMEOUT,5,process=rphost,p:processName=*****,t:clientID=16536,t:applicationName=1CV8,t:computerName=ASUSM,t:connectID=17272,SessionID= 2242,Usr=*******,WaitConnections=8239By the way, there can be several rphost_PID folders, it all depends on how many worker processes are running on the server.
And then everything is simple: look at the end of the line - WaitConnections = 8239, this is our CONNECTION number. We go to the server console, go to Connections, find this number and look at the session number. In my case, there were two sessions per user - a failed one and some other one. Crashed the session indicated by the technical log. And about a miracle! Everything worked, there is no limit to joy! But, as it turned out later, the session was not hung :), they worked in it. Therefore, for the future, it is advisable to contact the user and warn.
In my opinion, a fairly typical solution to a fairly typical problem. It is not known why I did not come across it, perhaps due to the fact that I had to look for it on alarm, and when users did not press, then it was not possible to conduct tests - there was no error.
When hundreds of users work with programs and data at the same time, there are problems inherent only in large-scale solutions. We are talking about problems caused by data locks.
Sometimes users find out about locks from messages that indicate the inability to write data or perform some other operation. Sometimes due to a very significant drop in program performance (for example, when the time required to perform an operation grows tens or hundreds of times).
The problems caused by blocking do not have a general solution. Therefore, we will try to analyze the causes of such problems and systematize options for their solution.
REASONS FOR TRANSACTION BLOCKING
Let's first remember what locks are, and at the same time we will figure out if they are needed. Let's look at a couple of classic examples of blocking that we encounter in life.
Example 1: Buying a plane or train ticket. Suppose we voiced our wishes to the cashier. The cashier tells us the availability of seats, from which we can choose the one we like the most (if there are several, of course). Until we choose and confirm our agreement with the proposed option, these seats cannot be sold to anyone else, i.e. temporarily blocked. If they were not blocked, then by the time of confirmation there could be a situation where the tickets we have chosen have already been sold. And in this case, the selection cycle can be an unpredictable number of repetitions. While we are choosing places, but they have already been sold! .. While we are choosing others, and they are no longer there ...
Example 2: buying something in a store or market. We went up to the counter, chose the most beautiful apple out of a hundred available. They chose and reached into their pocket for money. What will it look like if, while we are counting the money, it is the apple we have chosen that will be sold to the buyer who came up later than us?
Thus, blocking in itself is a necessary and useful phenomenon. It is thanks to blocking that we guarantee the execution of actions in one stage. And most often not the most successful implementation leads to negative software when, for example:
- an excessive number of objects (tickets, apples) is blocked;
- blocking time is unreasonably extended.
EXCESSIVE INTERLOCKS IN TYPICAL 1C CONFIGURATIONS
On major projects As a rule, we use 1C:Enterprise. That's why practical advice We will try to describe the solutions to blocking problems using the example of the 1C:Enterprise + MS-SQL bundle.
The 8th generation of 1C:Enterprise provides a very, very good parallelism of use. Simultaneously with one configuration (that is, on one base), with normal servers and communication channels, it can work great amount users. For example, hundreds of storekeepers process the issuance or receipt of goods, economists simultaneously calculate the cost of wages according to various departments, calculators carry out the calculation and calculation of wages, etc.
But there is a reason why there is an opinion to the contrary - the myth that, with intensive simultaneous use, it is uncomfortable or impossible to work with solutions based on 1C: Enterprise. After all, as soon as hundreds of users begin to use standard solutions for 1C:Enterprise on an industrial scale, more and more often a window appears on the screen with a proud inscription: “Error when calling the context method (Record): Lock conflict while executing a transaction: ...” and further into depending on the type of SQL server used, something like “Microsoft OLE DB Provider for SQL Server: Lock request time out period exceeded. ...".
Almost all standard solutions in the proposed "out of the box" implementation are configured for automatic lock management. "Automatic" here can be taken as "paranoid". Just in case, when conducting any document, we block everything that can be somehow connected with it. So it turns out that when one user spends something (and sometimes just writes), the rest can only wait.
I will express my opinion why 1C decided not to customize its standard solutions for high parallelism of use. Labor costs for such refinement are not high - a few "person-months", which is not significant in terms of 1C scale. I think the reason is different.
Firstly, such a refinement significantly complicates the processors for posting all documents. This means that for those consumers who use 1C for small tasks, without any gain there will be only a drawback - the complexity of finalizing a typical configuration will become more complicated. At the same time, statistics suggest which category of customers is the main feeder for 1C ...
The second reason is buried in typical basic settings SQL servers, such as MS-SQL, which is still used more often than others. It just so happened that the priorities in the settings are given to saving server RAM, and not to reducing blocking. This leads to the fact that, if it is necessary to lock several rows, the SQL server takes an “economical” decision for memory and processor - to lock the entire table at once!..
Here are the flaws standard solutions or the specifics of the database server setup being used are often conflated with problems caused by locks. As a result, technical flaws lead to very significant organizational problems. After all, if an employee is given a reason to be distracted from work or justified why the work could not be done, a minority will work effectively. Well, a message about blocking transactions or a “slowing down” program is an ideal justification why nothing could be done.
RECOMMENDATIONS FOR ELIMINATION OF EXCESSIVE BLOCKING FOR 1C:ENTERPRISE
What to do if the solution of problems of excessive blocking is so important?
At the final stage of implementation of all large complexes, it is necessary to carry out a fine refinement in order to eliminate unnecessary transaction locks. It is critical to resolve problems that may arise from insufficiently developed blocking conditions or implementation methodology.
Because this operation extremely important, it must be carried out constantly. Therefore, to simplify the implementation of such a refinement, we have developed a number of basic recommendations that we try to adhere to. Recommendations received and tested on the experience of a significant number of large-scale implementations.
- If your DBMS or development system (for example, 1C:Enterprise) uses automatic data locking mode by default, discard automatic control locks. Set up blocking rules yourself, describe the blocking criteria for entire tables or individual rows.
- When developing a program, whenever possible, refer to the tables in the same order.
- Try not to write to the same table multiple times within the same transaction. If this is difficult, then at least minimize the amount of time between the first and last write operation.
- Analyze the possibility of disabling lock escalation at the SQL server level.
- Clearly inform users about the reasons for the impossibility of performing any actions if they are due to blocking. Give accessible and understandable recommendations on what to do next.
If you look closely at the recommendations, it becomes clear that such development is appropriate not only for 1C:Enterprise, but for any systems. It doesn't matter what language they are written in and what database server they work with. Most of the recommendations are of a universal nature, and therefore are equally valid when using 1C: Enterprise, and for "self-written" programs or other "boxed" ERP systems.
P.S. Did you know that we offer professional assistance with updating 1C software best price?
Search Tags:- Transaction locks
- Removing blockages
- Blocking 1C
- blocking
- Lock Conflict
- Lock conflict while executing a transaction
On multi-user systems important role plays proper organization structures and setting locks. If not, users will often encounter errors caused by competition for certain system resources. But there is a lock conflict problem that many users are familiar with. Why does a 1C lock conflict occur and how to fix it?
Lock conflict in 1C 8.3 and its meaning
For most users, a 1C lock conflict message means only an error that prevents them from doing their job. They want to get rid of this problem as soon as possible and besiege the IT department with complaints that "1C does not work."
But for system administrators and developers, such a message indicates a possible problem in the configuration structure. Before trying to please users and remove blocks, you need to analyze the situation and understand the cause of the error message.
Causes of blocking errors in 1C
Demonstrative load tests demonstrate that the 1C server can withstand the parallel operation of more than five thousand users. But the ideal conditions for such experiments are unattainable in the daily conditions of large and medium-sized companies. To achieve similar performance and error-free performance, the configuration must be ideally designed and tailored to the specific business processes of the enterprise.
If you do not take ideal options, then 1C lock conflicts occur for the following reasons:
Simultaneous work of users with a large amount of data. This root cause is dictated by the internal mechanisms of 1C. They imply the prohibition of changing the data involved in a transaction launched on behalf of another user;
Errors and shortcomings in the configuration. The structure of standard solutions from the company "1C" takes into account recommendations for maximizing productivity. But third-party developers do not always adhere to high standards, and you can often find the following shortcomings in their code:
- Suboptimal requests;
- Request for balances at the beginning of actions;
- Misunderstanding the purpose of configuration objects and their incorrect use;
- Redundancy inherent in the system or additionally developed locks.
How to fix a lock conflict in 1C 8.3
The system message "lock conflict during the execution of transaction 1C 8.3" does not characterize the configuration as incorrectly designed. But if such signals are ignored, then there is a possibility that at the most crucial moment, for example, when submitting quarterly or annual reports, you will get big problems. At best, a slowing system and dissatisfied users. At worst, incorrect output data, which can lead to penalties from regulatory authorities.
The solution to the problem of the conflict of locks in 1C 8.3 can be the transfer of the configuration to a managed (manual) lock management mode. Implemented in version 8.1, the mechanism in the hands of competent specialists solves the problem of lock conflicts during transactions in 1C.
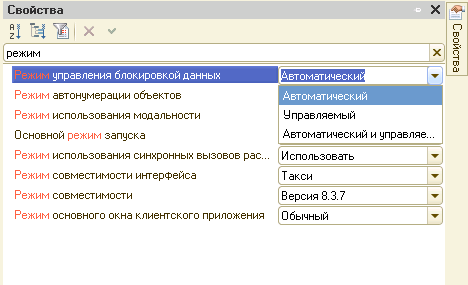
But it should be borne in mind that this action will reduce the level of protection of data from changes in the process of reading them by other users. Therefore, if you are not ready to independently control all the locks in the system, do not rush to change the configuration settings.
Quick resolution of 1C lock conflict
In the work of an administrator or developer, there may be a situation where there is no time to check the error and find the root causes of the problem. For example, you need to submit a report or submit data by a certain time, and 1C blocking errors prevent this.
There are two ways to quickly solve the problem:
- Find and end the session that has locked the required data. IN small companies, where the number of 1C users does not exceed a couple of dozen people, this is the best solution;
- If you control a system that has hundreds of employees, finding the right session without specialized software can take a long time. In this case, it will be much more efficient to restart the server.
These solutions are radical and aimed only at a quick solution to the problem and the release of data for urgent reporting. It can be eradicated only by understanding the reason due to which a lock conflict arose during the execution of a 1C transaction. After such actions, it is necessary to find vulnerabilities in the system, optimize the configuration or work of employees. It is not recommended to use such measures on a permanent basis with regular conflicts of locks on transactions.